However...
cat <<EOF | sed -e's/\\input{\(.*\)}/\1.tex/' | xargs touch
\input{intro}
\input{cha1}
\input{cha2}
\input{cha3}
\input{cha4}
\input{cha5}
\input{conclusions}
EOF
cat <<EOF | sed -e's/\\input{\(.*\)}/\1.tex/' | xargs touch
\input{intro}
\input{cha1}
\input{cha2}
\input{cha3}
\input{cha4}
\input{cha5}
\input{conclusions}
EOF
The first thing I have to say is that this post actually contains my own reflections. I have not found clear scientific facts that actually prove these ideas wrong or right. On the other hand, if you have evidence (in both directions) I'd be glad to have it.
On of my first contacts with probability distributions was probably around 7-8th grade. My maths teacher was trying to explain to us the concept of gaussian distribution, and as an example, he took the grade distribution. He claimed that most of the students get average results and that comparatively fewer students got better or worse grades (and the more "extreme" grades were reserved for a few).
I heard similar claims from many teachers of different subjects and I have not been surprised. It looks reasonable that most people are "average" with fewer exceptionally good or exceptionally bad exemplars. The same applies to lots of different features (height, for example).

Lots of years later, I read a very interesting paper claiming that, instead the distribution of programming results usually has two humps. For me, the paper was sort of an epiphany. In fact, my own experience goes in that direction (but here, I may be biased because I have not collected data). The paper itself comes with quite lot of data and examples, though.
So apparently there are two models to explain the distribution of human skills: the bell and the camel. My intuition is that for very simple abilities, the distribution is expected to be a gaussian. Few people have motivation to become exceptionally good, but the thing is simple enough that few remain exceptionally bad either. On the other hand, sometimes there is simply some kind of learning barrier. It's like a big step that not everybody is able to make. This is common for non-entirely trivial matters.
In this case, the camel is easily explained. There are people who climbed the step and people who did not. Both groups are internally gaussian distributed. Another example could be an introductory calculus exam. If the concepts of limit and continuity are not clear, everything is just black magic. However, some person may still get decent marks because of luck or a lower level form of intuition. Among those that have the fundamental concepts clear there is the usual gaussian distribution.
However, both models essentially assume that the maximum amount of skill is fixed. In fact, they are used to fit grades, that have, by definition, a maximum and a minimum value. Not every human skill has such property. Not every human skill is "graded" or examined in a school like environment. And even for those that actually are, usually grades are coarse grained. There is probably a big difference between a programming genius (like some FOSS super stars) and a regular excellent student. Or between, say, Feynman and an excellent student taking full marks. The same thing may be even more visible for things usually perceived as artistic. Of course, it is hard to devise a metric that can actually rank such skills.
My idea is that for very hard skills, the distribution is more like a power law (at least in the tail). Very few people are good, most people are not even comparable to those and the probability to find someone twice as good as a very good candidate is just a fraction.
Just to conclude, I believe that for very simple skills most of the time we have a gaussian. If we have "learning steps" or some distinctive non-continuous feature that is related, then we have multi-modal distributions (like the camel for programming: those that are able to build mental models of the programs are successful, those that only use trial and error until the programs "compile" are unsuccessful). Eventually, for skills related to exceptionally hard (and challenging and gratifying) tasks we have power-law distributions. May we even use such distributions to classify the skills and the tasks? And in those cases, a gaussian distribution is a good thing or not?
So that, given someone that is able to make mental models of programs, maybe Haskell programming remains multi-modal, because there are some conceptual steps that go beyond basic programming, while Basic is truly gaussian? Is OOP gaussian? And FP?
And in OOP languages, what about static typing? Maybe dynamic typing is a camel (no, not because of Perl) because those that write tests and usually know what they are doing fall in the higher hump, while those that just mess around fall in the lower hump. Ideas?
I recently read Armstrong essay on how much OOP sucks. While such opinions would probably have considered pure blasphemy a few years ago, nowadays they are becoming more popular. So, what’s the matter with OOP?
The first thing that comes to mind is that OOP promised too much. As already occurred to other paradigms and ideas (e.g., Logic Programming and Artificial Intelligence) sometimes researchers promise too much and then they (or the industry) cannot stay true to their promises.
OOP promised better modularity, better code-reuse [0], better “whatever”. Problem is, bad developers write crap with every single programming paradigm out there. With crap I really mean “utter crap”. A good programmer using structured programming and a bad programmer using OOP, is that the good programmer’s structured program would probably look “more object oriented” than the other one.
Another problem occurred in the OOP community: OOP “done right” was about message-passing. Information Hiding, Encapsulation and the other buzz-words are a consequence of the approach (because object communicate with messages, their internal state is opaque) not a goal of OOP. Objects are naturally “dynamic” and the way we reason about code is separating concerns in objects having related concerns and having the objects communicate in order to achieve the task at hand. And I’m a bit afraid of talking about “OOP done right”: I really just have my vision. OOP is very under-specified, so that it becomes very hard to criticize (or defend) the approach.
However, OOP becomes “data + functions”. To me data is simply *not* part of OOP. It’s an implementation detail of how objects maintain state. As a consequence, I do not really see data-driven applications as good candidates to OOP. Once again, OOP was sold as universal. It is not. Consider the successes that functional programming is achieving (performance and concept-wise) in this area.
This “data + functions” comes from C++ being the first commercially successful OOP platform. The great advantage was that the transition from structured programming to OOP was quite more easier, that programs could be far more efficient (read “less runtime”) than message passing dynamic OOP systems, at least back in the day. However, there was so much missing from the original idea!
Since back then classes were considered good (and C++ had — and has — no separate concept of interface) + static typing and a relatively verbose language with no introspection, it became rather natural to focus on inheritance. Which later was proved to be a bad strategy. Consequently, there is less experience in building OO software than one would think, considering that for a large part of its history OOP was dominated by sub-optimal practices.
So, what is really bad with OOP? Following Armstrong:
Agreed! But I believe that Data Structures are not *truly* part of OOP. Let me explain.
Data is laid out in some way. There is a “physical layout”, for example. You can express that very precisely in C with extensions, to the point of exactly specifying the offsets of the various datas. A phyisical layout also exists in high level languages such as Python. However, it is not part of the Python model. Of course with the struct module or ctypes you can fiddle with it (but they are libraries), however, for the most part, it is just outside the conceptual language used to describe the problem.
Data is also laid out in logical ways. Computer Science defined many data structures and algorithms over them. You can use OOP to express such structures and such algorithms. Still they are not “part” of OOP, they are just expressed in an object oriented way (or maybe not, and remain at structured programming level).
One very good practice in OOP is not using together in the same body of code objects reasoning at different levels. So, for example, you have your low level business logic code that is expressed in terms of data structures, high level business logic expressed in terms of low level business code… and that’s it. Functions is not really together with data. You don’t have “data”. You have some layers of objects.
The point is that OOP is about creating languages at semantic level (you usually do not get to change the syntax). That’s it. If the language is good, well… good. If the language is bad, ok, we’ve got a problem.
Is this suboptimal? In a way, yes. All the indirection may be very expensive. And since abstractions, well… abstract, you may find yourself with a language that is not expressive enough (at least not at the expenses of additional performance costs). Still functions and data structure is not bound together. You just have objects and messages. No “functions” and no “data”. Please notice: this may not be the right thing to do. Still, the problem is not with data + functions, is just related to applying OOP to a specific domain that is ill suited for the approach. OOP is not for every task in the world. But the same objections applies to every system that is built as a stack of layered abstractions.
Please also consider the Qc Na story! Objects are not necessarily opposed to functional programming (you can see them as closures that make different actions available). Objects are just about state + behavior + identity.
And this is something that I don’t think is a problem. It is like saying that Scheme is bad because “everything is a list” (which, strictly speaking, is not true, there are atoms and lambdas etc). If you do not want to program OO, then don’t. If you want, you probably want that everything is an object.
The only issue with everything is an object is, sometimes, performance. From a variety of points of view, such strategy may kill performance. Objects usually have indirections (read pointer). 64 bit pointer for every integer is bad. So we have hybrid stuff like Java and then we have to deal with boxing (either manually in the past or automatically right now). Performance issues can be somewhat “fixed” using proper JIT systems or other optimization techniques. Or providing libraries that do the right thing (see Numpy, for example).
Other than that, I prefer objections in the line of “this thing that should be an object is something else” than those requesting that something that is an object really is. So, I can favorably consider an objection that says that, in Python, “if” is not an object (true). Even though I’m convinced that having if as a statement is not bad either.
And the whole objections with “time”… well, time (and dates) are a bitch to handle. But I find that Python datetime module gets as close to perfection as humanely possible. I really can’t see describing time with a bunch of enums + some structures as an improvement. On the other hand, it looks to me as one of the cases where it is *easy* to see that the OO approach works better.
Consider the related problem of representing a date in a locale. If you introduce a new representation of time, you need either to modify the original function or create a new function (maybe one that works with both things). Creating an interface, on the other hand makes it very easy to introduce new representations of time.
——
[0] someone once told me they feel lucky when they can actually use the code effectively once, let alone reusing it.
Today I finally pinpointed the worst bug I ever met. The bug itself manifested perhaps a week ago when I decided to plot the distribution of a given attribute in a simulator. Essentially, the distribution should have been a power-law but a different behavior occurred. Varying some parameters changed the shape of the curve, but not the fact that it was not a power law.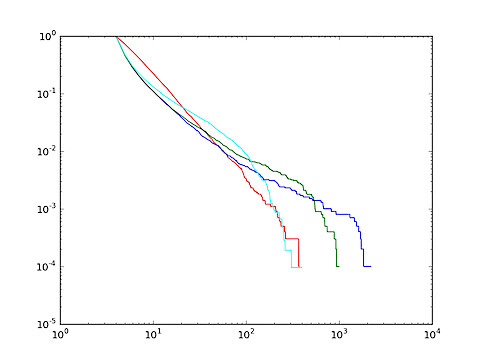
Here, in red the "expected curve", while the other three colors are the plots of the distributions I found (blue the original one, green and cyan variants with different parameters). The essential problem is that finding the exact cause of this was a hell. This kind of bugs is typically not found with unit-testing. In fact, the very problem is randomized and even mocking the random number generator does not really help. In fact, each individual event occurred apparently "right" and only the whole process showed a wrong behavior.
Since the simulation is concurrent, I spent the first days analyzing if the actual order of execution did somehow cause the problem (the red curve is obtained with a non concurrent model). Turns out that I did things right: event order did not influence the problem.
Eventually, I reviewed the drawing code (in the sense of urns, not in the sense of painting!). After a couple of days I figured out that perhaps I should have mathematically proved that the code implementing the draw had the same distribution of the "red" variant. My wrong assumption was that sampling a graph edge and taking one end-point was equivalent to an extraction from an urn where each node is placed n times, where n is its degree. Essentially the question is that even though the graph was undirected, the computer did ordered the edges end-points.
This is the distribution obtained taking the other endpoint:
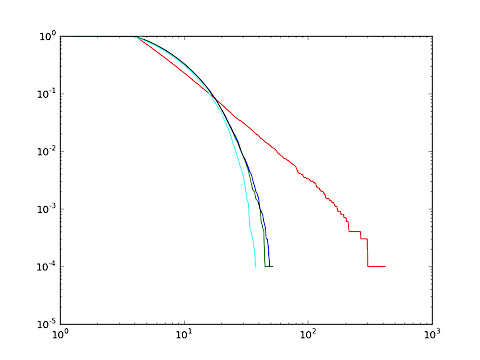
And here, eventually, what we got when I randomize between the two endpoints:

I just have to rewrite the code implementing the drawing. And I also have to make it fast (my former procedure was quite fast, given the fact that the whole graph is distributed).
(lambda it, sys: (
lambda n: (
lambda F, nxt: nxt(
map(
lambda dummy: (F(int) * F(raw_input))(),
it.takewhile(lambda m: m < n, it.count()))
))(
type('F+', (object, ), {
'__init__' : lambda self, f: setattr(self, 'f', f),
'__mul__': lambda self, g:
type(self)(lambda *stuff: self.f(g(*stuff))),
'__call__': lambda self, *stuff: self.f(*stuff)}),
lambda seq: sys.stdout.write(
"%d %f" % (
sum(seq),
sum(seq)/float(len(seq))))))(10))(
__import__('itertools'),
__import__('sys'))
For me, the transition to lion was relatively painless. Painless here basically means that I patched up the couple of things that gave me problems . In the specific situation, the issue is that Apple's new developer's tools do not include regular gcc anymore. Instead there is a version working with llvm backend which is great but has some issues with some packages that have not been updated yet.
Another problem is that is closely related is that I had a Python 2.7 installed with Python main website package. I did this because older OS Xs did not have Python 2.7. That Python was built with the older gcc-4.0 apple shipped with SL. Thus, new libraries I install with pip still want that compiler, which apple moved in /Developers-3.2.x/... Thus, I lived so far adding that directory to the PATH and happily compiling.
What I should have done was getting rid of my beloved python and either use EPD or Apple built-in 2.7 (shipping with Lion) or use a brew-ed python or see if Python.org distributes a Python compiled with the new compiler (which, as far as I know, is perfectly capable of building Python). The question is: are there any python extension I need that need the older gcc? But this is not something I'm going to discuss here: not yet ready to make the transition.
I just want to point out that I installed the old gcc from homebrew-alt, and now I can just brew install --use-gcc for packages that need the old gcc compiler. This is easy to use and nice. I also removed the old Developers and hope everything's fine.
% git clone https://github.com/adamv/homebrew-alt.git /usr/local/LibraryAlt % brew install /usr/local/LibraryAlt/duplicates/apple-gcc42.rb
An older version of gfortran I installed conflicted, but the commands above worked like a charm after removing it.
Once upon a time, in the land of the Clojure, there was a brilliant student who enquired the nature of things and he for that he was greatly loved and appreciated by his teachers, for he was brilliant and asked about the nature of things and they could explain him the world. He learned about macros and first order functions and actors and software transactional memory and he was happy. But then he began to focus on the nature of recur and he felt that something was amiss and the way trampolines and functions interact made him wonder.
During a short holiday he was in Schemeland, and he saw that they did not use recur. They named the functions and called them with their name in tail position and that was the way they did. And he felt it was good. So he asked his Master:
"Why can the schemers call the functions in tail position and their stacks never end?"
And the Master told him that it was because their soil is fertile, while the land of the Clojure is just an oasis in the wastes of Javaland.
"We are lucky," he added, "for our land still gives us food spontaneously and the air does not drives us mad. And our spring is natural and not a framework. And if you do not like recur, you can always map, for or loop. Higher order functions and macros can help you to hide what you do not like, for you are the master of your own language."
For a while the student was content, still he had a recurring thought: functions can do everything and in Church he did not find recur but only functions. And so he learned Y. But Y is a demanding beast, for it requires functions to be defined awkwardly. And the student wanted to simply write:
(defn factorial [n acc]
(if (= n 0)
acc
(factorial (- n 1) (* n acc))))
His Master saw him troubled and in pain, and one day a big application they were creating exploded with a StackOverflowError and he knew that unless the student was cured he could not be writing code with the others. So one evening, he told his student that if he really wanted to learn the secrets to make tail-call recursive functions run with constant stack usage, he shall go to the Land of Snakes, where they eat only Spam and Eggs, to look for some wise men and have them teach the secrets of creating tail recursion at language level. And he warned the student that the travel was dangerous.
The young student was frightened, because the Land of Snake is far away and he was barely aware of the perils that lurked in the shadow. However, his resolve was strong and he packed his things, an editor and few jars to survive the wastes of Javaland, and ventured forth. He travelled through the dull wastes where everything is private or protected and he has to ask things to do things for him. But as most people grew up in the land of Clojure, he knew that objects are but closure in disguise and he new how to bind them to his will with the power of the dot form.
After three days and three nights he eventually reached the Mines of Ruby and where massive gates blocked his way. He spoke the words as his master instructed (password: mellon), but the gate remained closed, for someone monkey-patched it and the door now spoke english, but the student did not know it and with failure in his heart he left the place, because he was trained in the ways of Lambda and could not cope with such a stateful abomination.
After months of wandering, he eventually reached Schemeland, where he at least could tail recur without recur. He spent another month drowning his pain into first class continuations and losing hope to ever come back to the land of Clojure, until one day he overhead the men telling tales at the tavern about a pythonista adventuring to Schemeland. The student sought the pythonista and eventually he found him and he asked him about the secrets of recursion and the pythonista showed him code and the student was happy because he knew classes are another word for closures and he was a master of closures. But he also understood that state was the missing element and he was saddened, because he also knew that state is treacherous.
Nonetheless, he felt he had come to far to be stopped by the formal purity of stateless programming and he eventually wrote the code. Little is known of what happened afterwards. Some claim he finally found his way to the lend of the Snake, after having extendedly monkey-wrenched the monkey patcher, other say that he went back to the Land of the Clojure.
I, your humble narrator, do not know the truth. I tried nonetheless to follow the student's step and implement myself the function that makes tail recursive calls without using recur. Ugly it is, and is indeed but an illusion, for recur lies inside the implementation. Still, it does the trick:
(defrec factorial [n acc] (if (= n 0) acc (factorial (- n 1) (* n acc))))
And here the code:
(defn uuid [] (str (java.util.UUID/randomUUID))) (defn tail-recursive [f] (let [state (ref {:func f :first-call true :continue (uuid)})] (fn [& args] (let [cont (:continue @state)] (if (:first-call @state) (let [fnc (:func @state)] (dosync (alter state assoc :first-call false)) (try (loop [targs args] (let [result (apply fnc targs)] (if (= result cont) (recur (:args @state)) result))) (finally (dosync (alter state assoc :first-call true))))) (dosync (alter state assoc :args args) cont))))))
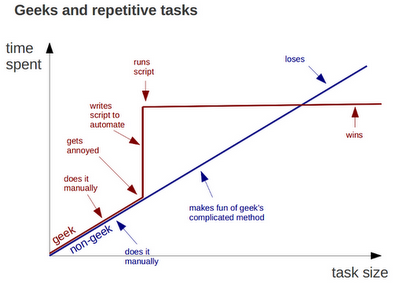
About automation, I'm definitely a geek. And I totally agree with the famous graph:
And I was working to a Java project with an unusual deployment. Part of the problem is that the actual application for which I was writing the plugin wasn't available as a maven repository. Moreover, running the whole thing needed some fiddling with long command line options, plus a non-trivial class-path.
I started appreciating maven with leiningen, and then by itself. Moreover, it solves one of the worse problems I have with IDEs. I hate to version IDE files (after all, people may use a different environment, something many eclipse users do not even consider). And I hate to recreate them every time (especially when they are not trivial). Eventually, I hate to depend from a GUI program to actually build a project (where a command line should suffice).
Then there is another problem related to libraries, i.e., I find it annoying all the solution regarding jars:
Maven solves all these problems together. I just name the jars in the pom and everything is taken care of. I loved the thing so much with Clojure and Leiningen that even with the despicable xml syntax things work smoothly.
But I had this very important jar that ain't versioned nowhere. So maven was out of question, I thought: moreover. The idea of manually downloading the jar and then adding it to maven's repository (and doing it on the 2-3-4 computer I use) really looked unacceptable.
So I dig into ant most advanced stuff and built an ant script that actually downloaded the jar for me and put it in a lib directory inside the project (packaging jars with the project is not acceptable). But I still wanted to use maven… so I learned the terribly documented ant plugin to get the dependencies from maven… and since that was not installed by default, I also wrote the code to go and get the jar.
So I basically had this ant script that did everything for me… and was some hundred lines long. Eventually, I also wrote some targets to generate scripts to execute the project (I told about complex command lines).
Of course, this also meant that maven was under-used. But then I realized… I have maven. I have a plugin that creates the scripts for me (not part of maven, but maven can easily get it). I only need ant to get the ant-maven bridge (which I wouldn't need anymore) and to get the missing jar. So I'm maintaining a very complex system for basically nothing: it is so much simpler to wget the jar, install it in the local maven repository and go on.
Fun that in order not to write to lines a couple of times I wrote a one hundred lines script.
The original vision Alan Key had on object oriented programming was about separate entities communicating through message passing. A logical consequence is that the global programming state is the sum of the individual states of these entities (called objects). State of such objects is naturally hidden from the outside and state modifications occur only as a consequence of the exchanged messages.
I would like to mention that in this model the "privacy" of internal variables is not exactly simply a matter of a keyword, but a consequence of a programming philosophy. This is not the kind of limitation you get in Java classes or C++, where the field is there, you just cannot access it. It somewhat more similar to calling a black-box with a state that is its own business; there are no fieldsand if there are, they are just an implementation detail. Or even more so, private variables are not accessed in the same sense that the physical address of an object in Java is not part of the programming model.
Such objects do not necessarily have their own thread of execution (in the sense that they are concurrently in control). However, if they had, the logical model would not be overly different. But back to the objects…
I somewhat believe that objects are an overloaded metaphor. In fact, there are at least two types of objects. And while the object oriented message only metaphor well applies for domain specific objects, I somewhat feel that it is not appropriate for some data structures. Sometimes, it is a nice property that "similar structures" have a common interface so that, for example, switching from an array to a linked-list is a painless transition, because it eases experimentation with different trade-offs regarding computational efficiency (although such problems are better solved with pen and paper).
However, in other situations, accessing the internals of some complex structure is plainly the "right thing to do". It is a walking-horror from the object oriented point of view, but it plainly makes sense for computational reasons. I often have to deal with graphs with billions of nodes, and more often than not I feel that usual OO laws are too restrictive.
A clear example here is the design of networkx.Graph: I have nothing against the design, by the way. I believe they do the right thing. Here the idea is that they have implemented their Graph internals in some way (does not matter how, right now). However, you may want to get a list of all the nodes in the graph. Now, how to do this? The first issue, is that the nodes may not be memorized in a way which is easier to return. This is actually the case: nodes are a dictionary keys, under the hood. So essentially there is no easy way to return them without calling some dict member which returns a newstructure holding the nodes.
OOP is all about state change. Perhaps just local state change, if done correctly. And hopefully the state's effect do not propagate too far from where the state is hidden. About C++, I found no other very mainstream OO language that makes it clear what you shall change and what you shall not.
The C++ pragmatics is really precise on consting whatever you can const. And to solve issues where it is not practical to have a logically const object which actually mutates something inside, you can use the mutable modifier to support the idea that the object realstate did not change while some irrelevant parts of it indeed changed. Examples are forms of caching, counting stuff, logging to a logger we hold a reference to.
Another important aspect of C++ is that it quite distinguishes between a const pointer (a pointer that cannot change) and a pointer to a const object (the pointed object cannot change). As always all this leads to additional complexity. However, declaring stuff const is good: first it is a rather strong safety guarantee, second it really leads to optimizations otherwise impossible. Still, it is tragically inadequate wrt. plainly immutable objects.
Moreover, although many other languages do not have pointer arithmetics, they do have references. In Java it is possible, for example, to mark such a reference final, which essentially means it will always refer to a given object. However, there is no way to state that the actual object could not be mutated by accesses through that specific reference.
In Java, the only way to achieve that goal is not providing methods that mutate the state. In fact this approach makes sense. Somewhat you make the language simpler without really losing much. And C++ newbies really do not get the whole constness thing very well.
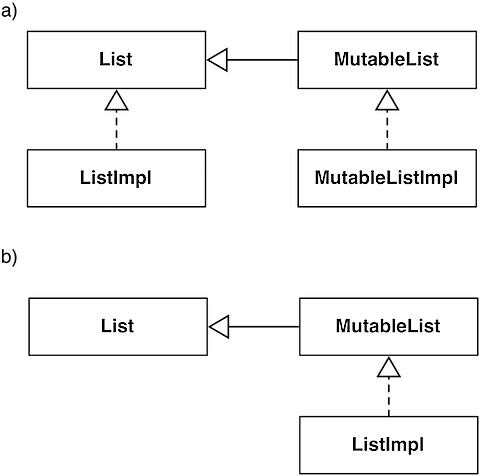
Essentially, in Java you do not have the possibility to have a mutable object that some clients cannot mutate. There are options, however. For example, in Figure 1) we have two interfaces, one mutable and one immutable. We have the mutable interface extend the immutable one and the appropriate base classes.
Immutability at class level can be obtained both (a) with a true immutable implementation implementing the immutable interface and a mutable implementation implementing the mutable one; or (b) with just a mutable implementation: clients that should not mutate the object will use the immutable interface. This is quite similar to the const in C++ in the sense that a const_cast is usually possible (and in this case we could just cast to the mutable interface). Such things somewhat break the whole immutability thing, but sometimes have their uses.
And what is the big deal with immutability? Basically, in this context immutable stuff can be shared with no fear. And copying huge datasets is too inefficient to be considered.
The essential problem here is that the OO language we have discussed so far are built around the idea that your co-workers will screw the project if they can do stuff. So the objective is not letting them do it. Constness shall be enforcedby the language (you had the opinion that I was happy about C++ const, did you?) because otherwise someone will foobar the project.
On the other hand in languages such as Python you may well do everything to every object and consequently the const-enforcement does not fare very well. A bit more could be done (formally) in Ruby. Still, even then you could always hack the objects to let you do whatever you want. And believe me, you could do that also in C++ and Java, provided you have sufficient control of the environment where the program is going to be run. It is just way harder.
In fact, I believe approaches where good policies about code isolation can be also (easily) implemented in Python. Good API design is of paramount importance. A C++ wise advise (from Meyers) was "Avoid returning Handles to object internals" (Item 28, Effective C++, 3rd ed, Scott Meyers, Addison-Wesley).
Essentially the idea is never to let your object guts exposed and never ever let someone mess with it. This is not about trust. This is about such handles are just a sure way to break your object constraints (why I'm talking like a static programmer anyway?). The point is that such handles change state independently by the core object and this is probably going to be bad, because the corruption of the state will be revealed in a place and time extremely distant from when and where it actually happen.
So, we have to carefully design our APIs, even (shall I say, especially?) if we are dynamic programmers. For example, we can return views on our object internals. Since our languages are very dynamic, such views can be easily constructed: they just have to quack like the original objects. When it makes sense, it is probably just better place the functionality in the "large" object and to delegate to the attribute (delegation is so trivial to implement in dynamic languages!). Notice that strongly interface based languages such as Java could make this approach even more natural, provided that formally specified interfaces make sense for the specific case.
Sometimes it makes also sense to return object which can mutate and where their mutation influences the state of the object from which they come from. However, in this situations such objects shall be built in a way that they do not break the behavior of the object from which they were gotten. Essentially here we are just obeying principle like SRP (single responsibility principle) and design things to work together. In fact, they are not handles to the object internals at all. We are not exposing the implementation of the object: we are just exposing an interface to a part of the object state (perhaps even state that cannot be changed through the main object interface).
What are the problems with this approach? As long as things are not modified, copying is fine. A view is a good thing, because it may be as efficient as possible for reading, while being completely safe. The problem essentially arises when we want to mutate the objects state: internals handles are bad, so we have to:
1. carefully craft the object interface to allow modifications efficiently and that make sense to the problem at hand, without making it excessively general (because it clashes with efficiency) or excessively big (because it clashes with almost every good property OOP tries to give to programs)
2. Perhaps create special objects that are able to perform controlled modifications on the original object. This may give lot of generality, in a sense, but also complicates the class hierarchy significantly.
Back to our example… we may have many solutions. Suppose that this "get the list of nodes" operation is frequent enough. It may make sense to memorize such list separately from the dictionary. If node removal and addition is not too frequent, the additional memory may well be worth it (well, perhaps not, if we really have lots of nodes). Even if such operations are frequent, we double the cost of the addition and make deletion O(N)… but if instead of a list we use a set, we have both operation O(1) simply with an increased multiplicative constant. Of course a language could offer a dict implementation which essentially offers an efficient view over the set of keys, so that separate memorization is not needed.
We could use a mutable datatype to hold the list, but then we should make a copy before returning it (this what actually happens with networkx). Not making a copy has the same problems of returning an internal handle. If we make a copy, then we could return something immutable or mutable. Essentially returning something immutable has not a lot of sense, as modifications would not affect the graph andmodifications to the graph are not reflected in the node-list. The simplest thing to do is plainly return a list of nodes.
The true solution would be that dictionary supported a "true" view object which is able to modify the original dictionary. And actually Python 2.7 and Python 3 have it. At this point we could just return such thing and have both efficiency and functionality… were it not for a simple issue: a networkx graph has more than one internal structure holding the nodes. Thus a higher level view would need to be created which could work across the different point were the same information is memorized inside a Graph. And we are back to the "complicating the class hierarchy thing".
The thing is that actually having to specify things to be const, is a bit a pain. And perhaps it is just me... but consider the Java solutions (this apply to things which roughly work like Java): we are talking about having two class and two interfaces (or just one class and two interfaces) for lots of objects. In my opinion, this is not practical. And if we want to create "well-behaved handles" things become even more complex.
In fact, this is probably why it is not done (most of the times). Probably it should be sufficient to limit such strategies for things where it really matters. Think about the collections framework.
On the other hand... think about a world where most things are just immutable. I think it is just a safer mind model of programming. It is not about limiting your colleagues (or yourself) on not doing things which are licit in the model and that we want to restrict.
If we thinkimmutable, things are just easier. But then we are definitely moving towards the functional side of things. I'm not claiming that functional languages have onlyimmutable stuff. Even though many functional languages (Clojure, Haskell) have mostly immutable stuff. However, reasoning in terms of flows of functions and immutable objects is just easier than thinking about immutable immutable objects. At least, it should be, if we were trained to think functionally from the beginning.
Here we are used to deal with const objects. Sometimes we needto change the state. Two typical scenarios spring to mind. We aren't doing "Object Oriented Programming": we are just writing an algorithm and the algorithm was conceived for imperative languages. Sometimes there is no clear conversion into the functional world. Not an efficient one, at least. In this case we may want to use some special mutable object (arrays?) to perform our computation efficiently. And this may even generally work.
In the second case, it is simply not practical to structure the state of the world as some function parameters. In fact most of the times the global state is to big to be wisely represented as a huge set of parameters. In this case we probably want to express the computation as a set of transformations (functions, basically) that shall be executed one after the other on the world. Here I am mostly thinking about Haskell's monads. Though, even different from a syntactical and semantical point of view, we are not far from the realm of refs/agents.
The issue of efficiency, however, remains. We should still keep in mind that well buried under layers of object orientations there may be lots of hidden costs. Interfaces often get in the way of really efficient implementations, because costs are not part of the interface. The collections framework is beautiful… but sort is still implemented copying everything to an array and sorting the array.
Not only it is better to have const object by default, that is to say object mutability shall be an opt-in rather than an opt-out. In fact, a part from the famous koanabout objects and closures, we have to avoid returning handles to our objects guts… but I do not see often closures that open up the enclosed state to the world.
The point is that avoiding all the copy costs may be simply thething to do when we have to deal with huge datasets. Restrict mutability where needed (e.g., implementing the algorithms) but mostly use mutable input and outputs from functions. Moreover, functional code is generally flatter, which can also, in the long run, improve efficiency.
Eventually, with languages such as clojure, even the perceived drawbacks of lists can be avoided using vectors, which support efficiently a different sets of primitives. Lazyness is also extremely helpful: actions that are not performed do not cost.
One of the essential points is that we are using object for at least two different things: i) data-types and ii) domain objects. Data-types are usually general entities that can make sense in every program and are not particularly related to a specific application. Examples of these objects are numbers and strings, but also vectors, lists, maps. On the other hand domain objects are domain specific and depend on the specific context. Both a payroll system and a web-server have probably some use for a vector class, however web-server probably does not have an employee class.
The logic level of the objects of the two different kinds is different and code using both should not be written. Essentially, the idea is that low-level code should be encapsulated in methods or functions that work at an higher level, thus making the whole source more details because low level stuff does not clutter the flow of information. Also notice that most standard library code uses low-level abstractions, because it shall be rather domain independent. Thus better data structures mean better code.
So what are these data-types? Languages differ greatly in their choice of datatypes. C has only integers and arrays, for example (ok, it is not OO, but does not matter right now). C++ inherit this. Strings are a library function, so are more well behaved collections. The interesting thing is that the different parts of the STL do not depend much on each other. So for example streams do not play really well with strings (e.g., file names cannot be strings, but in fact streams do not play well with about everything else) and std::string does not have a method such as
vector<string> string::split(string sep);
or, better:
some_range<String> string::split(string sep);
In Java, we have Strings, but collections were retro-fitted. So for example String#split returns an array of strings. In my opinion, one of the essential problems of many "static" programming languages such as C++ and Java is right here: they have the wrong primitives. Writing low level code, is very cumbersome and unnecessarily imperative (C++ STL somewhat makes an exception as it has a somewhat functional flavor the rest of the language lack).
I think that having entities that fit a similar role but have very different usage places a heavy conceptual burden. In Java arrays are really different from collections: they have a nice ugly syntax (but at least they have one) and cannot be used in the same ways collections can. Have different methods, names, facilities. On the other hand, collections lack a literal syntax, which is something that makes them feel "first-class". C++ has basically the very same problem; however, the STL does a great job in normalizing access patterns between STL collections and regular arrays.
Back to the main subject, I feel that Java actually lacks algorithmic code that eases manipulation of collections. In fact, the only "user-friendly" feature is the "for-each" statement. Other than that, code is very imperative and comparable with C code manipulating the same structures. Plus, Maps are really ugly because a first class tuple data-type is missing.
Clojure, on the other hand, has plenty of functions to manipulate low level stuff. This is rather relevant as there is a lot of code that works at this level. Being able to write it quicky is very important. Moreover, using the correct abstractions, avoid bugs. Consider for example the map functions? In a col like
(map f coll)
there can be only one single point of failure: what f does on the single elements. There is no explicit looping, no offset problems, nothing. Consider for example the number of things that can go wrong imperatively writing a loop that calls a function on pairs of consecutive elements in a collection. Compare it with its functional equivalent:
(let [coll (range 10)] (map + coll (rest coll)))
Here nothing can go really wrong. It is easier to write and easier to understand (provided you know a bit of clojure). It is worth noting that real high level object oriented languages have almost this kind of abstraction. But hey, they also have FOF and LOL (first order functions and let ovel lambda -- actually, they do not have let, but the name doesn't matter, does it?). Besides, that kind of code may also be easier to parallelize (in the sense that the compiler could do it).
Then comes class specific code. Object are great, fine. However, sometimes they are just used to group data together. In a sense, it makes sense. In Java there are no tuples, maps are ugly as hell and have the stupid requirement of type uniformity. Which means that either we abuse Object or we can't use them at all.
As a consequence, many specific classes are created. They have no true purpose, but carrying around pieces of data together. And that is just the task for maps, tuples, vectors. Maps, tuples and vectors have a uniform interface, "do the right thing" regardless of the types (in a decently typed language -- new definition… both static, e.g., Haskell, and dynamic, e.g., Clojure, Ruby, Python, languages can qualify! ). And there are plenty of functions to manipulate such stuff.
I think that one of the clearest examples is the Python tuple. A tuple is not magic. Is not clever. It is simple. Still, while in Python functions return only single values, tuples in fact allow to simulate multiple return values. And that is something which is overly useful in many different situations. In Clojure vectors can be used with a similar meaning (in fact, Clojure vectors are quite similar to Python tuples). And the destructuring syntax is amazing (once again, both in Python and in Clojure).
for k, v in some_map:
do_something_with(k, v)
or
(for [[k v] some-map] (do-something-with k v)) (doseq [[k v] some-map] (do-something-with k v))
Amazingly enough, the set of orthogonal language features used in both languages is roughly the same. Consider that with using a Set[Map.Entry[K,V]] Map#getEntrySet method... here we have this new Entry class. And perhaps somewhere else we have a Pair class which basically does the same thing, but it is a separate type, with different methods and different usage patterns. In dynamic languages at least, as long as the signature of the methods is compatible, something could be saved... but in statically typed object oriented languages, good luck with that.
I think these are some of the reasons I find especially pleasing writing algorithmic code in Python or Clojure and rather despise the very same thing in Java.