Introduction
The original vision Alan Key had on object oriented programming was about separate entities communicating through message passing. A logical consequence is that the global programming state is the sum of the individual states of these entities (called objects). State of such objects is naturally hidden from the outside and state modifications occur only as a consequence of the exchanged messages.
I would like to mention that in this model the "privacy" of internal variables is not exactly simply a matter of a keyword, but a consequence of a programming philosophy. This is not the kind of limitation you get in Java classes or C++, where the field is there, you just cannot access it. It somewhat more similar to calling a black-box with a state that is its own business; there are no fieldsand if there are, they are just an implementation detail. Or even more so, private variables are not accessed in the same sense that the physical address of an object in Java is not part of the programming model.
Such objects do not necessarily have their own thread of execution (in the sense that they are concurrently in control). However, if they had, the logical model would not be overly different. But back to the objects…
I somewhat believe that objects are an overloaded metaphor. In fact, there are at least two types of objects. And while the object oriented message only metaphor well applies for domain specific objects, I somewhat feel that it is not appropriate for some data structures. Sometimes, it is a nice property that "similar structures" have a common interface so that, for example, switching from an array to a linked-list is a painless transition, because it eases experimentation with different trade-offs regarding computational efficiency (although such problems are better solved with pen and paper).
However, in other situations, accessing the internals of some complex structure is plainly the "right thing to do". It is a walking-horror from the object oriented point of view, but it plainly makes sense for computational reasons. I often have to deal with graphs with billions of nodes, and more often than not I feel that usual OO laws are too restrictive.
Graph example
A clear example here is the design of networkx.Graph: I have nothing against the design, by the way. I believe they do the right thing. Here the idea is that they have implemented their Graph internals in some way (does not matter how, right now). However, you may want to get a list of all the nodes in the graph. Now, how to do this? The first issue, is that the nodes may not be memorized in a way which is easier to return. This is actually the case: nodes are a dictionary keys, under the hood. So essentially there is no easy way to return them without calling some dict member which returns a newstructure holding the nodes.
State and "Static" OOP
OOP is all about state change. Perhaps just local state change, if done correctly. And hopefully the state's effect do not propagate too far from where the state is hidden. About C++, I found no other very mainstream OO language that makes it clear what you shall change and what you shall not.
The C++ pragmatics is really precise on consting whatever you can const. And to solve issues where it is not practical to have a logically const object which actually mutates something inside, you can use the mutable modifier to support the idea that the object realstate did not change while some irrelevant parts of it indeed changed. Examples are forms of caching, counting stuff, logging to a logger we hold a reference to.
Another important aspect of C++ is that it quite distinguishes between a const pointer (a pointer that cannot change) and a pointer to a const object (the pointed object cannot change). As always all this leads to additional complexity. However, declaring stuff const is good: first it is a rather strong safety guarantee, second it really leads to optimizations otherwise impossible. Still, it is tragically inadequate wrt. plainly immutable objects.
Moreover, although many other languages do not have pointer arithmetics, they do have references. In Java it is possible, for example, to mark such a reference final, which essentially means it will always refer to a given object. However, there is no way to state that the actual object could not be mutated by accesses through that specific reference.
In Java, the only way to achieve that goal is not providing methods that mutate the state. In fact this approach makes sense. Somewhat you make the language simpler without really losing much. And C++ newbies really do not get the whole constness thing very well.
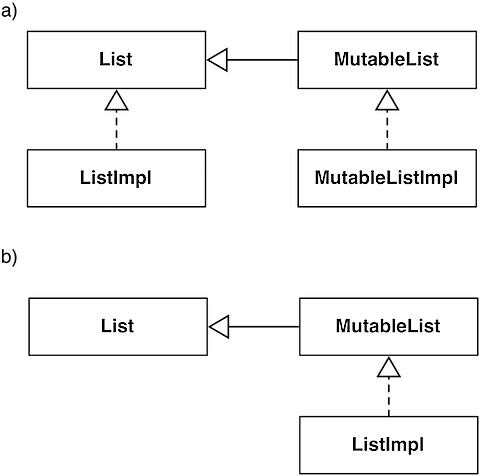
Essentially, in Java you do not have the possibility to have a mutable object that some clients cannot mutate. There are options, however. For example, in Figure 1) we have two interfaces, one mutable and one immutable. We have the mutable interface extend the immutable one and the appropriate base classes.
Immutability at class level can be obtained both (a) with a true immutable implementation implementing the immutable interface and a mutable implementation implementing the mutable one; or (b) with just a mutable implementation: clients that should not mutate the object will use the immutable interface. This is quite similar to the const in C++ in the sense that a const_cast is usually possible (and in this case we could just cast to the mutable interface). Such things somewhat break the whole immutability thing, but sometimes have their uses.
And what is the big deal with immutability? Basically, in this context immutable stuff can be shared with no fear. And copying huge datasets is too inefficient to be considered.
Dynamic OOP
The essential problem here is that the OO language we have discussed so far are built around the idea that your co-workers will screw the project if they can do stuff. So the objective is not letting them do it. Constness shall be enforcedby the language (you had the opinion that I was happy about C++ const, did you?) because otherwise someone will foobar the project.
On the other hand in languages such as Python you may well do everything to every object and consequently the const-enforcement does not fare very well. A bit more could be done (formally) in Ruby. Still, even then you could always hack the objects to let you do whatever you want. And believe me, you could do that also in C++ and Java, provided you have sufficient control of the environment where the program is going to be run. It is just way harder.
In fact, I believe approaches where good policies about code isolation can be also (easily) implemented in Python. Good API design is of paramount importance. A C++ wise advise (from Meyers) was "Avoid returning Handles to object internals" (Item 28, Effective C++, 3rd ed, Scott Meyers, Addison-Wesley).
Essentially the idea is never to let your object guts exposed and never ever let someone mess with it. This is not about trust. This is about such handles are just a sure way to break your object constraints (why I'm talking like a static programmer anyway?). The point is that such handles change state independently by the core object and this is probably going to be bad, because the corruption of the state will be revealed in a place and time extremely distant from when and where it actually happen.
So, we have to carefully design our APIs, even (shall I say, especially?) if we are dynamic programmers. For example, we can return views on our object internals. Since our languages are very dynamic, such views can be easily constructed: they just have to quack like the original objects. When it makes sense, it is probably just better place the functionality in the "large" object and to delegate to the attribute (delegation is so trivial to implement in dynamic languages!). Notice that strongly interface based languages such as Java could make this approach even more natural, provided that formally specified interfaces make sense for the specific case.
Sometimes it makes also sense to return object which can mutate and where their mutation influences the state of the object from which they come from. However, in this situations such objects shall be built in a way that they do not break the behavior of the object from which they were gotten. Essentially here we are just obeying principle like SRP (single responsibility principle) and design things to work together. In fact, they are not handles to the object internals at all. We are not exposing the implementation of the object: we are just exposing an interface to a part of the object state (perhaps even state that cannot be changed through the main object interface).
What are the problems with this approach? As long as things are not modified, copying is fine. A view is a good thing, because it may be as efficient as possible for reading, while being completely safe. The problem essentially arises when we want to mutate the objects state: internals handles are bad, so we have to:
1. carefully craft the object interface to allow modifications efficiently and that make sense to the problem at hand, without making it excessively general (because it clashes with efficiency) or excessively big (because it clashes with almost every good property OOP tries to give to programs)
2. Perhaps create special objects that are able to perform controlled modifications on the original object. This may give lot of generality, in a sense, but also complicates the class hierarchy significantly.
Graph example
Back to our example… we may have many solutions. Suppose that this "get the list of nodes" operation is frequent enough. It may make sense to memorize such list separately from the dictionary. If node removal and addition is not too frequent, the additional memory may well be worth it (well, perhaps not, if we really have lots of nodes). Even if such operations are frequent, we double the cost of the addition and make deletion O(N)… but if instead of a list we use a set, we have both operation O(1) simply with an increased multiplicative constant. Of course a language could offer a dict implementation which essentially offers an efficient view over the set of keys, so that separate memorization is not needed.
We could use a mutable datatype to hold the list, but then we should make a copy before returning it (this what actually happens with networkx). Not making a copy has the same problems of returning an internal handle. If we make a copy, then we could return something immutable or mutable. Essentially returning something immutable has not a lot of sense, as modifications would not affect the graph andmodifications to the graph are not reflected in the node-list. The simplest thing to do is plainly return a list of nodes.
The true solution would be that dictionary supported a "true" view object which is able to modify the original dictionary. And actually Python 2.7 and Python 3 have it. At this point we could just return such thing and have both efficiency and functionality… were it not for a simple issue: a networkx graph has more than one internal structure holding the nodes. Thus a higher level view would need to be created which could work across the different point were the same information is memorized inside a Graph. And we are back to the "complicating the class hierarchy thing".
Immutable by default
The thing is that actually having to specify things to be const, is a bit a pain. And perhaps it is just me... but consider the Java solutions (this apply to things which roughly work like Java): we are talking about having two class and two interfaces (or just one class and two interfaces) for lots of objects. In my opinion, this is not practical. And if we want to create "well-behaved handles" things become even more complex.
In fact, this is probably why it is not done (most of the times). Probably it should be sufficient to limit such strategies for things where it really matters. Think about the collections framework.
On the other hand... think about a world where most things are just immutable. I think it is just a safer mind model of programming. It is not about limiting your colleagues (or yourself) on not doing things which are licit in the model and that we want to restrict.
If we thinkimmutable, things are just easier. But then we are definitely moving towards the functional side of things. I'm not claiming that functional languages have onlyimmutable stuff. Even though many functional languages (Clojure, Haskell) have mostly immutable stuff. However, reasoning in terms of flows of functions and immutable objects is just easier than thinking about immutable immutable objects. At least, it should be, if we were trained to think functionally from the beginning.
Here we are used to deal with const objects. Sometimes we needto change the state. Two typical scenarios spring to mind. We aren't doing "Object Oriented Programming": we are just writing an algorithm and the algorithm was conceived for imperative languages. Sometimes there is no clear conversion into the functional world. Not an efficient one, at least. In this case we may want to use some special mutable object (arrays?) to perform our computation efficiently. And this may even generally work.
In the second case, it is simply not practical to structure the state of the world as some function parameters. In fact most of the times the global state is to big to be wisely represented as a huge set of parameters. In this case we probably want to express the computation as a set of transformations (functions, basically) that shall be executed one after the other on the world. Here I am mostly thinking about Haskell's monads. Though, even different from a syntactical and semantical point of view, we are not far from the realm of refs/agents.
The issue of efficiency, however, remains. We should still keep in mind that well buried under layers of object orientations there may be lots of hidden costs. Interfaces often get in the way of really efficient implementations, because costs are not part of the interface. The collections framework is beautiful… but sort is still implemented copying everything to an array and sorting the array.
Welcome under the sign of the Lambda
Not only it is better to have const object by default, that is to say object mutability shall be an opt-in rather than an opt-out. In fact, a part from the famous koanabout objects and closures, we have to avoid returning handles to our objects guts… but I do not see often closures that open up the enclosed state to the world.
The point is that avoiding all the copy costs may be simply thething to do when we have to deal with huge datasets. Restrict mutability where needed (e.g., implementing the algorithms) but mostly use mutable input and outputs from functions. Moreover, functional code is generally flatter, which can also, in the long run, improve efficiency.
Eventually, with languages such as clojure, even the perceived drawbacks of lists can be avoided using vectors, which support efficiently a different sets of primitives. Lazyness is also extremely helpful: actions that are not performed do not cost.