Introduction
Study of algorithms and data structures is a major field in computer science. Efficiently representing and processing data has been of paramount importance since the early days of computing. Many problems are simply not accessible without proper study, since the computational complexity used to overwhelm older machines.Today, we have powerful machines. Tomorrow, we will have more powerful and “more parallel” machines. One day, our computers will surpass the computing power of our own brain. However, no matters how fast the computer it is, there are always problems which are too hard, too expensive and, in short, intractable.
Essentially, the cost of the algorithm depends from the size of its input. For example, searching for an element in a list intuitively takes time proportional to the number of elements: after all, we don’t know where it is, we have to start somewhere and the element could be at the other end of the list.
In this case we say that the worst case is exactly A∙N, if A is the cost of comparing two elements and N is the length of the list. The average case is “only” A∙(N/2) since “in average” the element will be found after examining only half of the elements. Intuitively, the probability the element is the last one, is equal to the probability it is the first one, and so one. Computing average case cost is usually harder than worst case cost, because involves probability and random variables.
Landau notation and estimates
The computational cost of algorithms is usually represented in a unified notation (called Landau notation, from the name of the famous mathematician who introduced the notation in the field of calculus). Essentially, we don’t care about the multiplicative constants in the costs (e.g., A, “the cost of comparing two elements”) as long as they are, well… constants. We usually say that an looking for an element in a list costs O(N), which means that the time is proportional to the size of the list itself.Most of the times, computing the cost of an algorithm is rather straightforward. Considering a strictly imperative setting, you essentially estimate the number of times you run the body of a loop. For example, let us consider
the following code:
M = {}
n = 4
for i in xrange(0, n):
for j in xrange(0, i):
M[i,j] = M[j,i] = i + j
print M
It is rather easy to see that if A is the cost of M[i,j] = M[j,i] = i + j, the whole thing costs (using presumed Gauss's formula):

That is to say it's O(N^2). A (correct) but coarse argument is that the internal loop runs i times, and i is at most n. So in the worse case it is n. The upper bound is used as an estimate n*n (again O(n*n)).
Things are not always that easy: sometimes the worse case is completely uninteresting. E.g., the most widely used simplex algorithm[0] has an exponential worse case cost. Exponential means that it essentially sucks. 2^1000 is a huge[1] number and 1000 is
The Master Theorem
A large class of algorithms are called "divide et impera"; a typical example is mergesort[2]. Here a trivial python implementation is given:def merge_sort(L):
if len(L) <= 1:
return L
else:
middle = len(L) / 2
left = merge_sort(L[:middle])
right = merge_sort(L[middle:])
return merge(left, right)
def merge(left, right):
i = j = 0
max_i = len(left)
max_j = len(right)
sorted_ = []
while i < max_i and j < max_j:
if left[i] < right[j]:
sorted_.append(left[i])
i += 1
else:
sorted_.append(right[j])
j += 1
if i < max_i:
sorted_.extend(left[i:])
else:
sorted_.extend(right[j:])
return sorted_
Of course, no Python user would use such functions. They use recursion instead of iteration, they are not particularly efficient, the "Timsort"[3] implemented in the Python library is far more efficient both algorithmically and code-wise. Algorithm books tell us that merge-sort has worse and average case O(N log N). As with most divide et impera algorithms, the result can be proved with ad hoc demostrations. However, I found extremely useful using the so-called master theorem[4]. This is essentially a swiss-knife result that gives us the complexity of an algorithm given the way the data is "divided" and "recomposed" (to rule, of course!). The complexity of the algorithm on an input of size n is T(n). f(n) is the cost done outside the recursive calls (e.g., the time needed to decompose and put together the data); a is the number of subproblems in the recursion and n/b is the size of the input of the subproblems. For example, in merge-sort a = 2 and b = 2. f(n) is proportional to the size of the input vector. The master theorem states that if: 
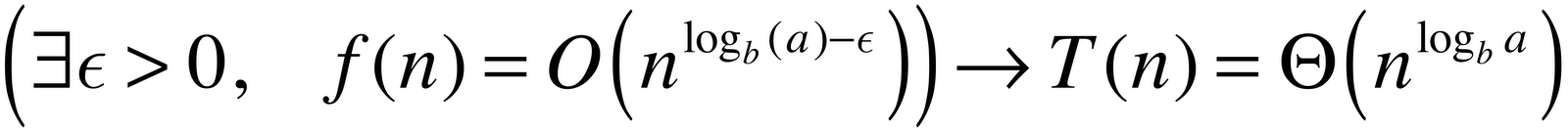

Notes
[0] http://en.wikipedia.org/wiki/Simplex_algorithm[1] 10715086071862673209484250490600018105614048117055336074437503883703510511249361224931983788156958581275946729175531468251871452856923140435984577574698574803934567774824230985421074605062371141877954182153046474983581941267398767559165543946077062914571196477686542167660429831652624386837205668069376
[2] http://en.wikipedia.org/wiki/Merge_sort [3] http://bugs.python.org/file4451/timsort.txt
[4] Introduction to Algorithms; Cormen, Leiserson, Rivest, and Stein; MIT Press